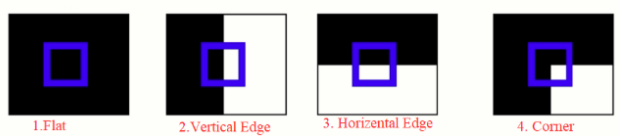
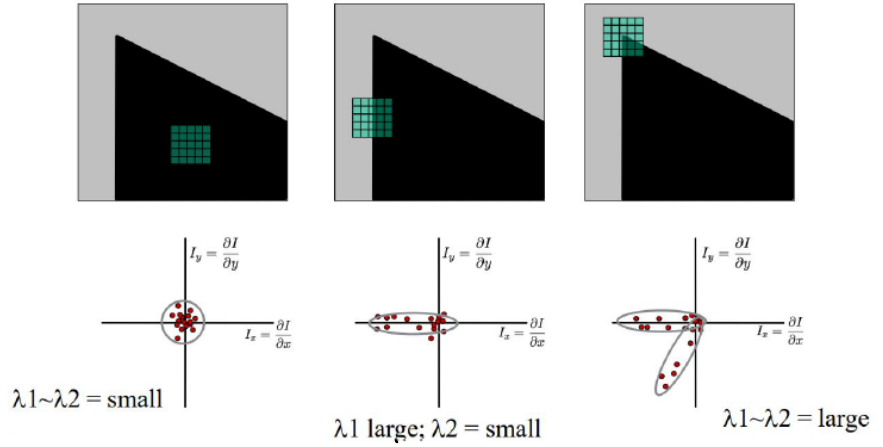
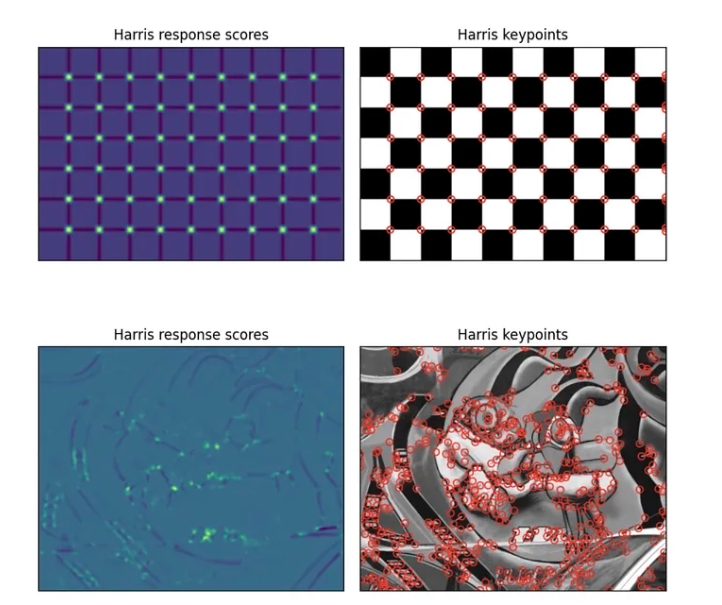
Visual Cheat Sheet Summary
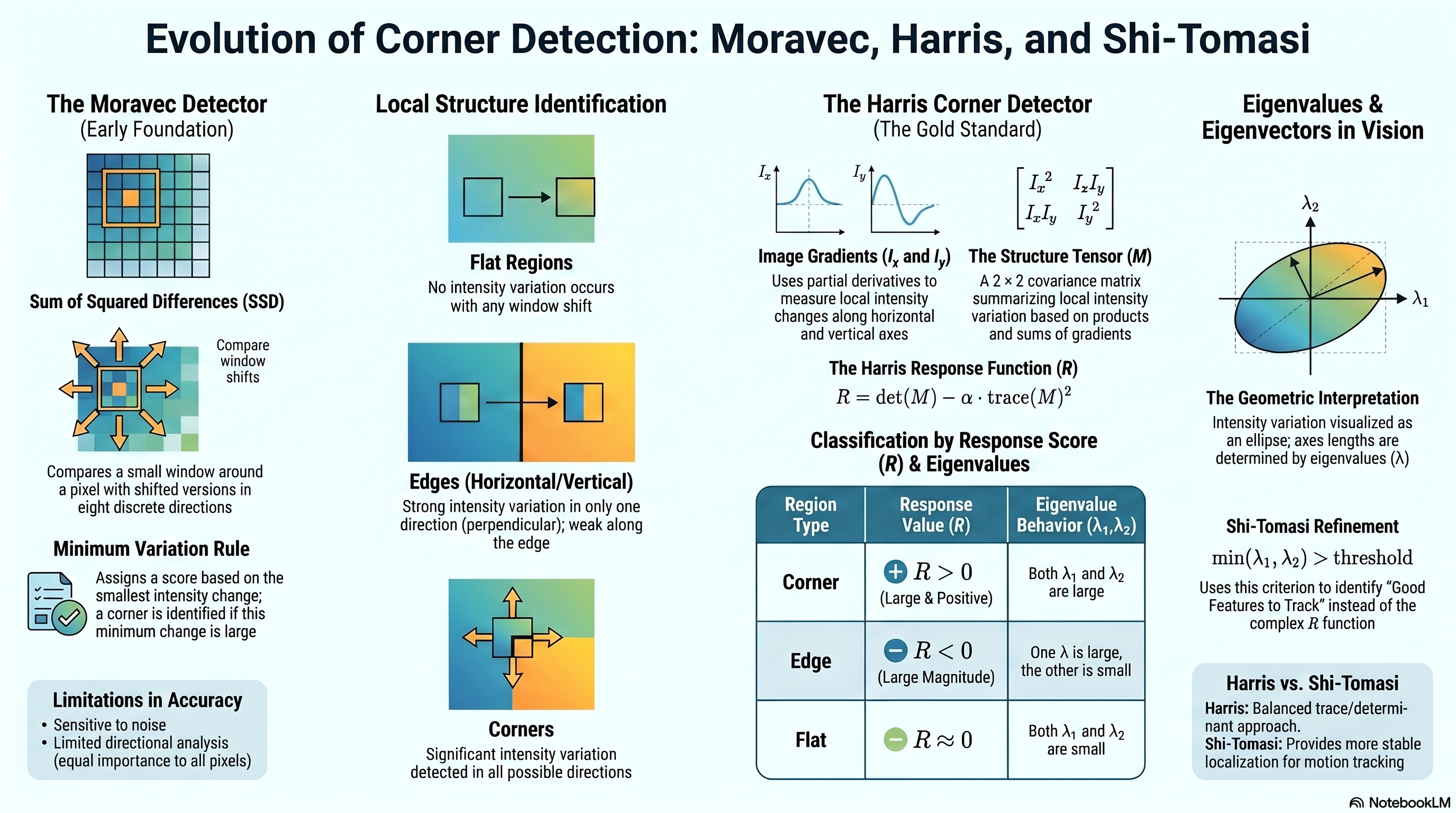
λ₁ ≈ 0, λ₂ ≈ 0
det ≈ 0, trace ≈ 0
No intensity change in any direction. Not an interest point.
λ₁ large, λ₂ ≈ 0 (or vice versa)
det ≈ 0, trace large
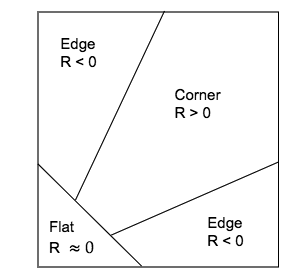
−α·trace² dominates → R negative. Change in one direction only.
λ₁ large AND λ₂ large
det large, trace large
det term dominates → R positive. Change in ALL directions.
| Property | Moravec | Harris | Shi-Tomasi |
|---|---|---|---|
| Intensity Measure | Sum of Squared Differences (SSD) | Structure tensor via gradients | Structure tensor via gradients |
| Directions Analyzed | 8 discrete shifts only | All continuous directions | All continuous directions |
| Window Type | Uniform rectangular | Gaussian weighted | Gaussian weighted |
| Response Function | min(SSD across 8 dirs) | det(M) − α·trace(M)² | min(λ₁, λ₂) |
| Free Parameter | None (threshold only) | α ∈ [0.04, 0.06] | None (threshold only) |
| Noise Sensitivity | High (no weighting) | Moderate (Gaussian window) | Moderate (Gaussian window) |
| Edge Sensitivity | High (min-SSD trick fails) | Lower (det/trace balance) | Low (direct λ comparison) |
| Rotation Invariant | No (axis-aligned only) | Yes | Yes |
| Computational Cost | Low | Low–Moderate | Moderate (eigenvalue solve) |
| Common Usage | Historical / educational | General corner detection | Tracking, optical flow |