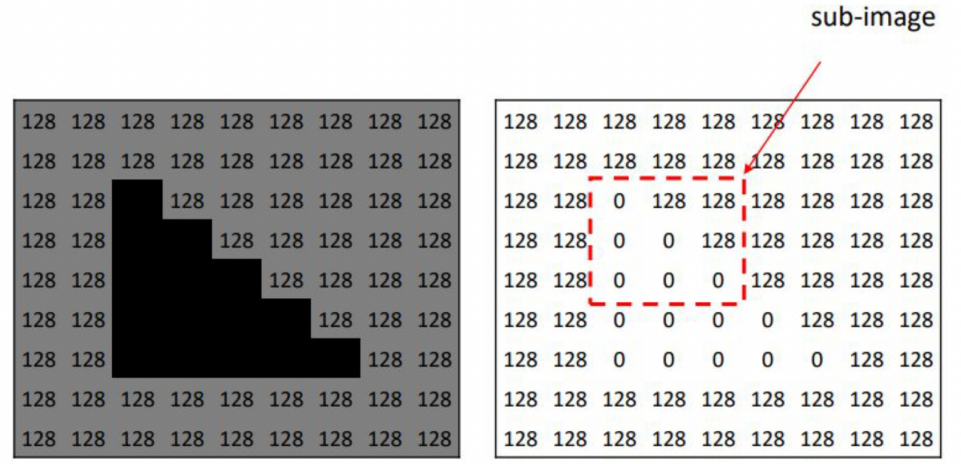
Consider a simplified image where background pixels have an intensity value of
128 (gray) and object pixels have a value of
0 (black). Let's trace how the Moravec detector evaluates a candidate pixel step-by-step:
1. Selecting the Reference Sub-Image
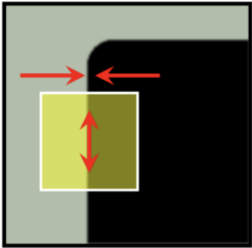
The detector places a small sliding window \(W\) (e.g., $2 \times 2$) centered at the candidate pixel location \((m,n)\) to capture the local intensity structure:
Original Window \(W\) at \((m,n)\):
\(I(m,n) = 0\) \(I(m,n+1) = 128\)
\(I(m+1,n) = 128\) \(I(m+1,n+1) = 128\)
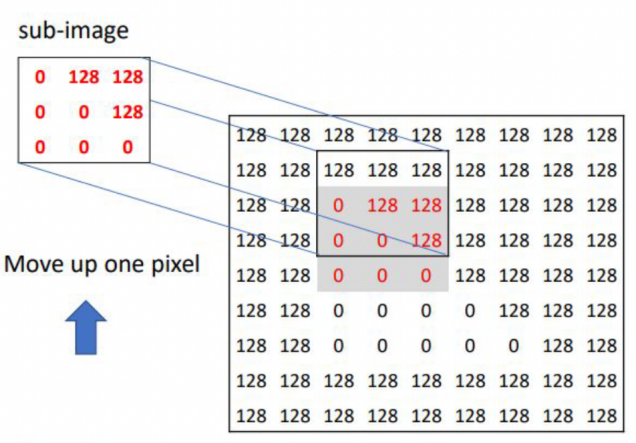
2. Shift Up by One Pixel: \((x,y) = (0, -1)\)
The sub-image is shifted one pixel upward and compared with the original window to evaluate intensity variation.
Shifted Window at \((m, n-1)\):
\(I(m, n-1) = 128\) \(I(m, n) = 0\)
\(I(m+1, n-1) = 128\) \(I(m+1, n) = 128\)
\[\text{SSD} = (0 - 128)^2 + (128 - 0)^2 + (128 - 128)^2 + (128 - 128)^2\]
\[\text{SSD} = 16384 + 16384 + 0 + 0 = 32768 \quad (\text{Large!})\]
A large SSD value indicates strong intensity variation when shifting upward, contributing evidence toward detecting a corner.
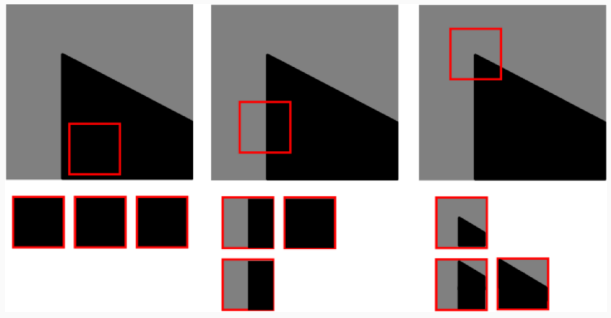
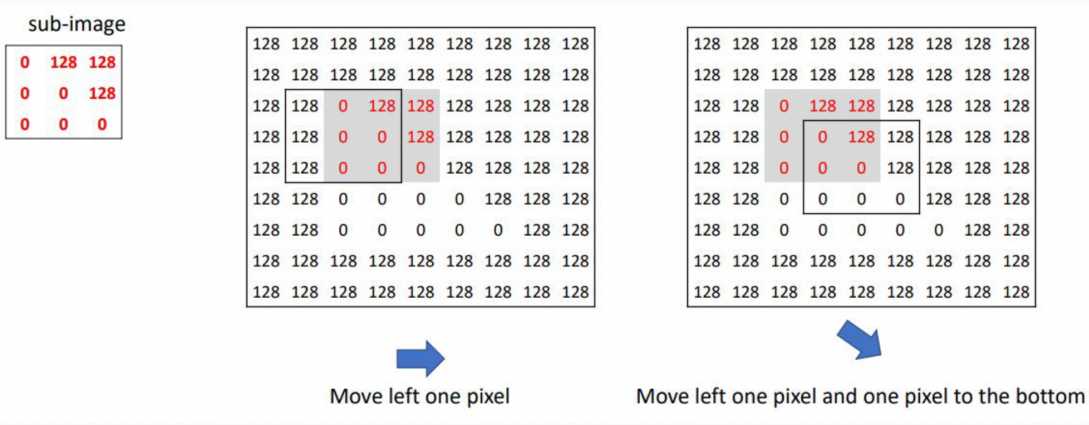
3. Horizontal, Vertical, and Diagonal Shifts
The process is repeated for shifts in other directions. Suppose we shift right:
Shifted Window at \((m, n+1)\) (Right shift):
\(I(m, n+1) = 128\) \(I(m, n+2) = 128\)
\(I(m+1, n+1) = 128\) \(I(m+1, n+2) = 128\)
\[\text{SSD} = (0 - 128)^2 + (128 - 128)^2 + (128 - 128)^2 + (128 - 128)^2\]
\[\text{SSD} = 16384 + 0 + 0 + 0 = 16384 \quad (\text{Large!})\]
If the window is shifted in a direction that aligns perfectly with an edge (e.g., shifting parallel to an edge), the pixel intensities will not change, resulting in a small SSD.
Only when the intensity variation remains large for
all tested shifts (meaning the minimum SSD \(F_{m,n}\) is still high) is the pixel classified as a corner.